Таким образом можно выделить следующие свойства коэффициента детерминации:
1. ; в силу определения
2. =0;в этом случае RSS = 0, т. е. наша регрессия не объясняет, ничего не дает по сравнению с тривиальным прогнозом. Данные позволяют сделать вывод о независимости y и x, изменение в переменной x никак не влияет на изменение среднего значения переменной y. То есть увеличивается разброс точек на корреляционном поле относительно построенной линии регрессии(или статистическая зависимость очень слабая, или уравнение регрессии подобрано неверно).
3. =1; в этом случае все точки () лежат на одной прямой (ESS = 0). Тогда на основании имеющихся данных можно сделать вывод о наличии функциональной, а именно, линейной, зависимости между переменными y и x. Изменение переменной y полностью объясняется изменением переменной x.Для парной линей регрессии коэффициент детерминации точно равен квадрату коэффициента корреляции:
Вообще говоря, значение коэффициента детерминации не говорит о том, есть ли между факторами зависимость и насколько она тесная. Оно говорит только о качестве того уравнения, которое мы построили.
Удобно сравнивать коэффициенты детерминации для нескольких разных уравнений регрессии построенных по одним и тем же данным наблюдений. Из нескольких уравнений лучше то, у которого больше коэффициент детерминации.
3. Скорректированный коэффициент детерминации
Одним из свойств коэффициента детерминации является то, что это не убывающая функция от числа факторов, входящих в модель. Это следует из определения детерминации. Действительно в равенстве
Числитель не зависит, а знаменатель зависит от числа факторов модели. Следовательно, с увеличением числа независимых переменных в модели, коэффициент детерминации никогда не уменьшается. Тогда, если сравнить две регрессионные модели с одной и тоже зависимой переменной, но разным числом факторов, то более высокий коэффициент детерминации будет получен в модели с большим числом факторов. Поэтому необходимо скорректировать коэффициент детерминации с учетом количества факторов, входящих в модель.
Скорректированный (исправленный или оцененный) коэффициент детерминации определяют следующим образом:

Свойства скорректированного коэффициента детерминации:
1. Несложно заметить что при >1 исправленный коэффициент детерминации меньше коэффициента детерминации ().
2. , но может принимать отрицательные значения. При этом, если скорректированный принимает отрицательное значение, то принимает значение близкое к нулю ().
Таким образом скорректированный коэффициент детерминации является попыткой устранить эффект, связанный с ростом R 2 при увеличении числа регрессоров. - "штраф" за увеличение числа независимых переменных.
Сoefficient of determination
Синонимы: Коэффициент смешанной корреляции
Статистический показатель, отражающий объясняющую способность уравнения регрессии и равный отношению суммы квадратов регрессии SSR к общейвариации SST:
где – уровень ряда,– смоделированное значение,– среднее по всем уровням ряда.
Данный показатель является статистической мерой согласия, с помощью которой можно определить, насколько уравнение регрессии соответствует реальным данным.
Коэффициент детерминации изменяется в диапазоне от 0 до 1. Если он равен 0, это означает, что связь между переменными регрессионной модели отсутствует, и вместо нее для оценки значения выходной переменной можно с таким же успехом использовать простое среднее ее наблюдаемых значений. Напротив, если коэффициент детерминации равен 1, это соответствует идеальной модели, когда все точки наблюдений лежат точно налинии регрессии , т.е. сумма квадратов их отклонений равна 0. На практике, если коэффициент детерминации близок к 1, это указывает на то, что модель работает очень хорошо (имеет высокую значимость), а если к 0, то это означает низкую значимость модели, когдавходная переменная плохо "объясняет" поведение выходной, т.е. линейная зависимость между ними отсутствует. Очевидно, что такая модель будет иметь низкую эффективность.
Коэффициент детерминации (R 2 )- это долядисперсии отклонений зависимой переменной от еёсреднего значения , объясняемая рассматриваемоймоделью связи (объясняющими переменными). Модель связи обычно задается как явная функция от объясняющих переменных. В частном случае линейной связиR 2 является квадратомкоэффициента корреляции между зависимой переменной и объясняющими переменными.
Общая формула для вычисления коэффициента детерминации:
![]()
где y i - наблюдаемое значение зависимой переменной, аf i - значение зависимой переменной предсказанное по уравнению регрессии-среднее арифметическое зависимой переменной.
При проверке гипотезы о наличии связи модель связи может быть неизвестна. Тогда ее задают в виде кусочно-постоянной функции (в этом случае коэффициент детерминации равен квадрату корреляционного отношения) либо оценивают неизвестные значения функции связи, используя методы сглаживания эмпирической зависимости (напримерметод скользящих средних ) .
Вариация признака определяется различными факторами, часть этих факторов можно выделить, если статистическую совокупность разделить на группы по определенному признаку. Тогда, наряду с изучением вариации признака по совокупности в целом, можно изучить вариацию для каждой из составляющих ее группы и между этими группами. В простом случае, когда совокупность разделена на группы по одному фактору, изучение вариации достигается посредством вычисления и анализа трех видов дисперсий: общей, межгрупповой и внутригрупповой.
Эмпирический коэффициент детерминации
Эмпирический коэффициент детерминации широко применяется в статистическом анализе и является показателем, представляющим долю межгруппопой дисперсии в результативного признака и характеризует силу влияния группировочного признака на образование общей вариации. Он может быть рассчитан по формуле:
Показывает долю вариации результативного признака у под влиянием факторного признака х, он связан с коэффициентом корреляции квадратичной зависимостью. При отсутствии связи эмпирический коэффициент детерминации равен нулю, а при функциональной связи - единице.
Например, когда изучается зависимость производительности труда рабочих от их квалификации коэффициент детерминации равен 0,7, то на 70% вариация производительности труда рабочих обусловлена различиями в их квалификации и на 30% - влиянием прочих факторов.
Эмпирическое корреляционное отношение - это квадратный корень из коэффициента детерминации. Отношение показывает тесноту связи между группировочным и результативным признаками. Эмпирическое корреляционное отношение принимает значения от -1 до 1. Если связи нет, то корреляционное отношение равняется нулю, т.е. все групповые средние равняются между собой и межгрупповой вариации нет. Значит, группировочный признак не влияет на образование общей вариации.
Если связь функциональная, то корреляционное отношение равняется единице. В таком случае дисперсия групповых средних равна общей дисперсии, т.е. внутригрупповой вариации нет. Это значит, что группировочный признак полностью определяет вариацию результативного признака.
Чем ближе значение корреляционного отношения к единице, тем сильнее и ближе к функциональной зависимости связь между признаками. Для качественной оценки силы связи на основе показателя эмпирического коэффициента корреляции можно использовать соотношение Чэддока.
Соотношение Чэддока
- Связь весьма тесная — коэффициент корреляции находится в интервале 0,9 — 0,99
- Связь тесная — Rxy = 0,7 — 0,9
- Связь заметная — Rxy = 0,5 — 0,7
- Связь умеренная — Rxy = 0,3 — 0,5
- Связь слабая — Rxy = 0,1 — 0,3
Коэффициент множественной детерминации характеризует, на сколько процентов построенная модель регрессии объясняет вариацию значений результативной переменной относительно своего среднего уровня, т. е. показывает долю общей дисперсии результативной переменной, объяснённой вариацией факторных переменных, включённых в модель регрессии.
Коэффициент множественной детерминации также называется количественной характеристикой объяснённой построенной моделью регрессии дисперсии результативной переменной. Чем больше значение коэффициента множественной детерминации, тем лучше построенная модель регрессии характеризует взаимосвязь между переменными.
Для коэффициента множественной детерминации всегда выполняется неравенство вида:
Следовательно, включение в линейную модель регрессии дополнительной факторной переменной xn не снижает значения коэффициента множественной детерминации.
Коэффициент множественной детерминации может быть определён не только как квадрат множественного коэффициента корреляции, но и с помощью теоремы о разложении сумм квадратов по формуле:

где ESS (Error Sum Square) – сумма квадратов остатков модели множественной регрессии с n независимыми переменными:
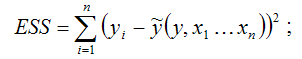
TSS (TotalSumSquare) – общая сумма квадратов модели множественной регрессии с n независимыми переменными:

Однако классический коэффициент множественной детерминации не всегда способен определить влияние на качество модели регрессии дополнительной факторной переменной. Поэтому наряду с обычным коэффициентом рассчитывают также и скорректированный (adjusted) коэффициент множественной детерминации, в котором учитывается количество факторных переменных, включённых в модель регрессии:

где n – количество наблюдений в выборочной совокупности;
h – число параметров, включённых в модель регрессии.
При большом объёме выборочной совокупности значения обычного и скорректированного коэффициентов множественной детерминации отличаться практически не будут.
24. Парный регрессионный анализ
Одним из методов изучения стохастических связей между признаками является регрессионный анализ.
Регрессионный анализ представляет собой вывод уравнения регрессии, с помощью которого находится средняя величина случайной переменной (признака-результата), если величина другой (или других) переменных (признаков-факторов) известна. Он включает следующие этапы:
выбор формы связи (вида аналитического уравнения регрессии);
оценку параметров уравнения;
оценку качества аналитического уравнения регрессии.
Наиболее часто для описания статистической связи признаков используется линейная форма. Внимание к линейной связи объясняется четкой экономической интерпретацией ее параметров, ограниченной вариацией переменных и тем, что в большинстве случаев нелинейные формы связи для выполнения расчетов преобразуют (путем логарифмирования или замены переменных) в линейную форму.
В случае линейной парной связи уравнение регрессии примет вид:
Параметры данного
уравнения а и b оцениваются по данным
статистического наблюдения x и y.
Результатом такой оценки является
уравнение:
![]() , где,- оценки параметров
a и b,
- значение
результативного признака (переменной),
полученное по уравнению регрессии
(расчетное значение).
, где,- оценки параметров
a и b,
- значение
результативного признака (переменной),
полученное по уравнению регрессии
(расчетное значение).
Наиболее часто для оценки параметров используют метод наименьших квадратов (МНК).
Метод наименьших квадратов дает наилучшие (состоятельные, эффективные и несмещенные) оценки параметров уравнения регрессии. Но только в том случае, если выполняются определенные предпосылки относительно случайного члена (u) и независимой переменной (x).
Задача оценивания параметров линейного парного уравнения методом наименьших квадратов состоит в следующем:
получить такие оценки параметров ,, при которых сумма квадратов отклонений фактических значений результативного признака - yi от расчетных значений – минимальна.
Формально критерий МНК можно записать так:
![]()
Проиллюстрируем суть данного метода графически. Для этого построим точечный график по данным наблюдений (xi ,yi, i=1;n) в прямоугольной системе координат (такой точечный график называют корреляционным полем). Попытаемся подобрать прямую линию, которая ближе всего расположена к точкам корреляционного поля. Согласно методу наименьших квадратов линия выбирается так, чтобы сумма квадратов расстояний по вертикали между точками корреляционного поля и этой линией была бы минимальной.

Математическая запись данной задачи:
![]()
Значения yi и xi i=1; n нам известны, это данные наблюдений. В функции S они представляют собой константы. Переменными в данной функции являются искомые оценки параметров - ,. Чтобы найти минимум функции 2-ух переменных необходимо вычислить частные производные данной функции по каждому из параметров и приравнять их нулю, т.е.
![]()
В результате получим систему из 2-ух нормальных линейных уравнений:

Решая данную систему, найдем искомые оценки параметров:

Правильность расчета параметров уравнения регрессии может быть проверена сравнением сумм
(возможно некоторое расхождение из-за округления расчетов).
Знак коэффициента регрессии b указывает направление связи (если b>0, связь прямая, если b <0, то связь обратная). Величина b показывает на сколько единиц изменится в среднем признак-результат -y при изменении признака-фактора - х на 1 единицу своего измерения.
Формально значение параметра а – среднее значение y при х равном нулю. Если признак-фактор не имеет и не может иметь нулевого значения, то вышеуказанная трактовка параметра а не имеет смысла.
Оценка тесноты связи между признаками осуществляется с помощью коэффициента линейной парной корреляции - rx,y. Он может быть рассчитан по формуле:

Кроме того, коэффициент линейной парной корреляции может быть определен через коэффициент регрессии b:
Область допустимых значений линейного коэффициента парной корреляции от –1 до +1. Знак коэффициента корреляции указывает направление связи. Если rx, y>0, то связь прямая; если rx, y<0, то связь обратная.
Если данный коэффициент по модулю близок к единице, то связь между признаками может быть интерпретирована как довольно тесная линейная. Если его модуль равен единице ê rx , y ê =1, то связь между признаками функциональная линейная. Если признаки х и y линейно независимы, то rx,y близок к 0.
Для оценки качества полученного уравнения регрессии рассчитывают теоретический коэффициент детерминации – R2yx:

где d 2 – объясненная уравнением регрессии дисперсия y;
e 2- остаточная (необъясненная уравнением регрессии) дисперсия y;
s 2 y - общая (полная) дисперсия y .
Коэффициент детерминации характеризует долю вариации (дисперсии) результативного признака y, объясняемую регрессией (а, следовательно, и фактором х), в общей вариации (дисперсии) y. Коэффициент детерминации R2yx принимает значения от 0 до 1. Соответственно величина 1-R2yx характеризует долю дисперсии y, вызванную влиянием прочих неучтенных в модели факторов и ошибками спецификации.
При парной линейной регрессии R 2yx=r2 yx.
Одним из показателей, описывающих качество построенной модели в статистике, является коэффициент детерминации (R^2), который ещё называют величиной достоверности аппроксимации. С его помощью можно определить уровень точности прогноза. Давайте узнаем, как можно произвести расчет данного показателя с помощью различных инструментов программы Excel.
В зависимости от уровня коэффициента детерминации, принято разделять модели на три группы:
- 0,8 – 1 — модель хорошего качества;
- 0,5 – 0,8 — модель приемлемого качества;
- 0 – 0,5 — модель плохого качества.
В последнем случае качество модели говорит о невозможности её использования для прогноза.
Выбор способа вычисления указанного значения в Excel зависит от того, является ли регрессия линейной или нет. В первом случае можно использовать функцию КВПИРСОН , а во втором придется воспользоваться специальным инструментом из пакета анализа.
Способ 1: вычисление коэффициента детерминации при линейной функции
Прежде всего, выясним, как найти коэффициент детерминации при линейной функции. В этом случае данный показатель будет равняться квадрату коэффициента корреляции. Произведем его расчет с помощью встроенной функции Excel на примере конкретной таблицы, которая приведена ниже.



Способ 2: вычисление коэффициента детерминации в нелинейных функциях
Но указанный выше вариант расчета искомого значения можно применять только к линейным функциям. Что же делать, чтобы произвести его расчет в нелинейной функции? В Экселе имеется и такая возможность. Её можно осуществить с помощью инструмента «Регрессия» , который является составной частью пакета «Анализ данных» .
- Но прежде, чем воспользоваться указанным инструментом, следует активировать сам «Пакет анализа» , который по умолчанию в Экселе отключен. Перемещаемся во вкладку «Файл» , а затем переходим по пункту «Параметры» .
- В открывшемся окне производим перемещение в раздел «Надстройки» при помощи навигации по левому вертикальному меню. В нижней части правой области окна располагается поле «Управление» . Из списка доступных там подразделов выбираем наименование «Надстройки Excel…» , а затем щелкаем по кнопке «Перейти…» , расположенной справа от поля.
- Производится запуск окна надстроек. В центральной его части расположен список доступных надстроек. Устанавливаем флажок около позиции «Пакет анализа» . Вслед за этим требуется щелкнуть по кнопке «OK» в правой части интерфейса окна.
- Пакет инструментов «Анализ данных» в текущем экземпляре Excel будет активирован. Доступ к нему располагается на ленте во вкладке «Данные» . Перемещаемся в указанную вкладку и клацаем по кнопке «Анализ данных» в группе настроек «Анализ» .
- Активируется окошко «Анализ данных» со списком профильных инструментов обработки информации. Выделяем из этого перечня пункт «Регрессия» и клацаем по кнопке «OK» .
- Затем открывается окно инструмента «Регрессия»
. Первый блок настроек – «Входные данные»
. Тут в двух полях нужно указать адреса диапазонов, где находятся значения аргумента и функции. Ставим курсор в поле «Входной интервал Y»
и выделяем на листе содержимое колонки «Y»
. После того, как адрес массива отобразился в окне «Регрессия»
, ставим курсор в поле «Входной интервал Y»
и точно таким же образом выделяем ячейки столбца «X»
.
Около параметров «Метка» и «Константа-ноль» флажки не ставим. Флажок можно установить около параметра «Уровень надежности» и в поле напротив указать желаемую величину соответствующего показателя (по умолчанию 95%).
В группе «Параметры вывода» нужно указать, в какой области будет отображаться результат вычисления. Существует три варианта:
- Область на текущем листе;
- Другой лист;
- Другая книга (новый файл).
Остановим свой выбор на первом варианте, чтобы исходные данные и результат размещались на одном рабочем листе. Ставим переключатель около параметра «Выходной интервал» . В поле напротив данного пункта ставим курсор. Щелкаем левой кнопкой мыши по пустому элементу на листе, который призван стать левой верхней ячейкой таблицы вывода итогов расчета. Адрес данного элемента должен высветиться в поле окна «Регрессия» .
Группы параметров «Остатки» и «Нормальная вероятность» игнорируем, так как для решения поставленной задачи они не важны. После этого клацаем по кнопке «OK» , которая размещена в правом верхнем углу окна «Регрессия» .
- Программа производит расчет на основе ранее введенных данных и выводит результат в указанный диапазон. Как видим, данный инструмент выводит на лист довольно большое количество результатов по различным параметрам. Но в контексте текущего урока нас интересует показатель «R-квадрат» . В данном случае он равен 0,947664, что характеризует выбранную модель, как модель хорошего качества.







Способ 3: коэффициент детерминации для линии тренда
Кроме указанных выше вариантов, коэффициент детерминации можно отобразить непосредственно для линии тренда в графике, построенном на листе Excel. Выясним, как это можно сделать на конкретном примере.
- Мы имеем график, построенный на основе таблицы аргументов и значений функции, которая была использована для предыдущего примера. Произведем построение к нему линии тренда. Кликаем по любому месту области построения, на которой размещен график, левой кнопкой мыши. При этом на ленте появляется дополнительный набор вкладок – «Работа с диаграммами» . Переходим во вкладку «Макет» . Клацаем по кнопке «Линия тренда» , которая размещена в блоке инструментов «Анализ» . Появляется меню с выбором типа линии тренда. Останавливаем выбор на том типе, который соответствует конкретной задаче. Давайте для нашего примера выберем вариант «Экспоненциальное приближение» .
- Эксель строит прямо на плоскости построения графика линию тренда в виде дополнительной черной кривой.
- Теперь нашей задачей является отобразить собственно коэффициент детерминации. Кликаем правой кнопкой мыши по линии тренда. Активируется контекстное меню. Останавливаем выбор в нем на пункте «Формат линии тренда…»
.

Для выполнения перехода в окно формата линии тренда можно выполнить альтернативное действие. Выделяем линию тренда кликом по ней левой кнопки мыши. Перемещаемся во вкладку «Макет» . Клацаем по кнопке «Линия тренда» в блоке «Анализ» . В открывшемся списке клацаем по самому последнему пункту перечня действий – «Дополнительные параметры линии тренда…» .
- После любого из двух вышеуказанных действий запускается окошко формата, в котором можно произвести дополнительные настройки. В частности, для выполнения нашей задачи необходимо установить флажок напротив пункта «Поместить на диаграмму величину достоверности аппроксимации (R^2)» . Он размещен в самом низу окна. То есть, таким образом мы включаем отображение коэффициента детерминации на области построения. Затем не забываем нажать на кнопку «Закрыть» внизу текущего окна.
- Значение достоверности аппроксимации, то есть, величина коэффициента детерминации, будет отображено на листе в области построения. В данном случае эта величина, как видим, равна 0,9242, что характеризует аппроксимацию, как модель хорошего качества.
- Абсолютно точно таким образом можно устанавливать показ коэффициента детерминации для любого другого типа линии тренда. Можно менять тип линии тренда, произведя переход через кнопку на ленте или контекстное меню в окно её параметров, как было показано выше. Затем уже в самом окне в группе «Построение линии тренда» можно переключиться на другой тип. Не забываем при этом контролировать, чтобы около пункта «Поместить на диаграмму величину достоверности аппроксимации» был установлен флажок. Завершив вышеуказанные действия, щелкаем по кнопке «Закрыть» в нижнем правом углу окна.
- При линейном типе линия тренда уже имеет значение достоверности аппроксимации равное 0,9477, что характеризует эту модель, как ещё более достоверную, чем рассматриваемую нами ранее линию тренда экспоненциального типа.
- Таким образом, переключаясь между разными типами линии тренда и сравнивая их значения достоверности аппроксимации (коэффициент детерминации), можно найти тот вариант, модель которого наиболее точно описывает представленный график. Вариант с самым высоким показателем коэффициента детерминации будет наиболее достоверным. На его основе можно строить самый точный прогноз.
Например, для нашего случая опытным путем удалось установить, что самый высокий уровень достоверности имеет полиномиальный тип линии тренда второй степени. Коэффициент детерминации в данном случае равен 1. Это говорит о том, что указанная модель абсолютно достоверная, что означает полное исключение погрешностей.

Но, в то же время, это совсем не значит, что для другого графика тоже наиболее достоверным окажется именно этот тип линии тренда. Оптимальный выбор типа линии тренда зависит от типа функции, на основании которой был построен график. Если пользователь не обладает достаточным объемом знаний, чтобы «на глаз» прикинуть наиболее качественный вариант, то единственным выходом определения лучшего прогноза является как раз сравнение коэффициентов детерминации, как было показано на примере выше.






