На сегодняшний день наука достаточно далеко продвинулась в разработке технологий прогнозирования. Специалистам хорошо известны методы нейросетевого прогнозирования, нечёткой логики и т.п. Разработаны соответствующие программные пакеты, но на практике они, к сожалению, не всегда доступны рядовому пользователю, а в то же время многие из этих проблем можно достаточно успешно решать, используя методы исследования операций, в частности имитационное моделирование, теорию игр, регрессионный и трендовый анализ, реализуя эти алгоритмы в широко известном и распространённом пакете прикладных программ MS Excel.
В данной статье представлен один из возможных алгоритмов построения прогноза объёма реализации для продуктов с сезонным характером продаж. Сразу следует отметить, что перечень таких товаров гораздо шире, чем это кажется. Дело в том, что понятие “сезон” в прогнозировании применим к любым систематическим колебаниям, например, если речь идёт об изучении товарооборота в течение недели под термином “сезон” понимается один день. Кроме того, цикл колебаний может существенно отличаться (как в большую, так и в меньшую сторону) от величины один год. И если удаётся выявить величину цикла этих колебаний, то такой временной ряд можно использовать для прогнозирования с использованием аддитивных и мультипликативных моделей.
Аддитивную модель прогнозирования можно представить в виде формулы:
где: F – прогнозируемое значение; Т – тренд; S – сезонная компонента; Е – ошибка прогноза.
Применение мультипликативныхмоделей обусловлено тем, что в некоторых временных рядах значение сезонной компоненты представляет собой определенную долю трендового значения. Эти модели можно представить формулой:
На практике отличить аддитивную модель от мультипликативной можно по величине сезонной вариации. Аддитивной модели присуща практически постоянная сезонная вариация, тогда как у мультипликативной она возрастает или убывает, графически это выражается в изменении амплитуды колебания сезонного фактора, как это показано на рисунке 1.
Рис. 1. Аддитивная и мультипликативные модели прогнозирования.
Алгоритм построения прогнозной модели
Для прогнозирования объема продаж, имеющего сезонный характер, предлагается следующий алгоритм построения прогнозной модели:
1.Определяется тренд, наилучшим образом аппроксимирующий фактические данные. Существенным моментом при этом является предложение использовать полиномиальный тренд, что позволяет сократить ошибку прогнозной модели.
2.Вычитая из фактических значений объёмов продаж значения тренда, определяют величины сезонной компоненты и корректируют таким образом, чтобы их сумма была равна нулю.
3.Рассчитываются ошибки модели как разности между фактическими значениями и значениями модели.
4.Строится модель прогнозирования:
где:
F– прогнозируемое значение;
Т
– тренд;
S
– сезонная компонента;
Е -
ошибка модели.
5.На основе модели строится окончательный прогноз объёма продаж. Для этого предлагается использовать методы экспоненциального сглаживания, что позволяет учесть возможное будущее изменение экономических тенденций, на основе которых построена трендовая модель. Сущность данной поправки заключается в том, что она нивелирует недостаток адаптивных моделей, а именно, позволяет быстро учесть наметившиеся новые экономические тенденции.
F пр t = a F ф t-1 + (1-а) F м t
где:
F ф t-
1 – фактическое значение объёма продаж в предыдущем году;
F м t
- значение модели;
а –
константа сглаживания
Практическая реализация данного метода выявила следующие его особенности:
- для составления прогноза необходимо точно знать величину сезона. Исследования показывают, что множество продуктов имеют сезонный характер, величина сезона при этом может быть различной и колебаться от одной недели до десяти лет и более;
- применение полиномиального тренда вместо линейного позволяет значительно сократить ошибку модели;
- при наличии достаточного количества данных метод даёт хорошую аппроксимацию и может быть эффективно использован при прогнозировании объема продаж в инвестиционном проектировании.
Применение алгоритма рассмотрим на следующем примере.
Исходные данные: объёмы реализации продукции за два сезона. В качестве исходной информации для прогнозирования была использована информация об объёмах сбыта мороженого “Пломбир” одной из фирм в Нижнем Новгороде. Данная статистика характеризуется тем, что значения объёма продаж имеют выраженный сезонный характер с возрастающим трендом. Исходная информация представлена в табл. 1.
Таблица 1.
Фактические объёмы реализации продукции
|
Объем продаж (руб.) |
Объем продаж (руб.) |
||||
|
сентябрь |
сентябрь |
||||
Задача: составить прогноз продаж продукции на следующий год по месяцам.
Реализуем алгоритм построения прогнозной модели, описанный выше. Решение данной задачи рекомендуется осуществлять в среде MS Excel, что позволит существенно сократить количество расчётов и время построения модели.
1. Определяем тренд , наилучшим образом аппроксимирующий фактические данные. Для этого рекомендуется использовать полиномиальный тренд, что позволяет сократить ошибку прогнозной модели).

Рис. 2. Сравнительный анализ полиномиального и линейного тренда
На рисунке показано, что полиномиальный тренд аппроксимирует фактические данные гораздо лучше, чем предлагаемый обычно в литературе линейный. Коэффициент детерминации полиномиального тренда (0,7435) гораздо выше, чем линейного (4E-05). Для расчёта тренда рекомендуется использовать опцию “Линия тренда” ППП Excel.

Рис. 3. Опция “Линии тренда”
Применение других типов тренда (логарифмический, степенной, экспоненциальный, скользящее среднее) также не даёт такого эффективного результата. Они неудовлетворительно аппроксимируют фактические значения, коэффициенты их детерминации ничтожно малы:
- логарифмический R 2 = 0,0166;
- степенной R 2 =0,0197;
- экспоненциальный R 2 =8Е-05.
2. Вычитая из фактических значений объёмов продаж значения тренда, определим величины сезонной компоненты , используя при этом пакет прикладных программ MS Excel (рис. 4).

Рис. 4. Расчёт значений сезонной компоненты в ППП MS Excel.
Таблица 2.
Расчёт значений сезонной компоненты
|
Месяцы |
Объём продаж |
Значение тренда |
Сезонная компонента |
Скорректируем значения сезонной компоненты таким образом, чтобы их сумма была равна нулю.
Таблица 3.
Расчёт средних значений сезонной компоненты
|
Месяцы |
Сезонная компонента |
||||
3. Рассчитываем ошибки модели как разности между фактическими значениями и значениями модели.
Таблица 4.
Расчёт ошибок
|
Месяц |
Объём продаж |
Значение модели |
Отклонения |
Находим среднеквадратическую ошибку модели (Е) по формуле:
Е= Σ О 2: Σ (T+S) 2
где:
Т-
трендовое значение объёма продаж;
S
– сезонная компонента;
О
- отклонения модели от фактических значений
Е= 0,003739 или 0.37 %
Величина полученной ошибки позволяет говорить, что построенная модель хорошо аппроксимирует фактические данные, т.е. она вполне отражает экономические тенденции, определяющие объём продаж, и является предпосылкой для построения прогнозов высокого качества.
Построим модель прогнозирования:
Построенная модель представлена графически на рис. 5.
5. На основе модели строим окончательный прогноз объёма продаж. Для смягчения влияния прошлых тенденций на достоверность прогнозной модели, предлагается сочетать трендовый анализ с экспоненциальным сглаживанием. Это позволит нивелировать недостаток адаптивных моделей, т.е. учесть наметившиеся новые экономические тенденции:
F пр t = a F ф t-1 + (1-а) F м t
где:
F пр t - прогнозное значение объёма продаж;
F ф t-1
– фактическое значение объёма продаж в предыдущем году;
F м t
- значение модели;
а
– константа сглаживания.
Константу сглаживания рекомендуется определять методом экспертных оценок, как вероятность сохранения существующей рыночной конъюнктуры, т.е. если основные характеристики изменяются / колеблются с той же скоростью / амплитудой что и прежде, значит предпосылок к изменению рыночной конъюнктуры нет, и следовательно а ® 1, если наоборот, то а ® 0.
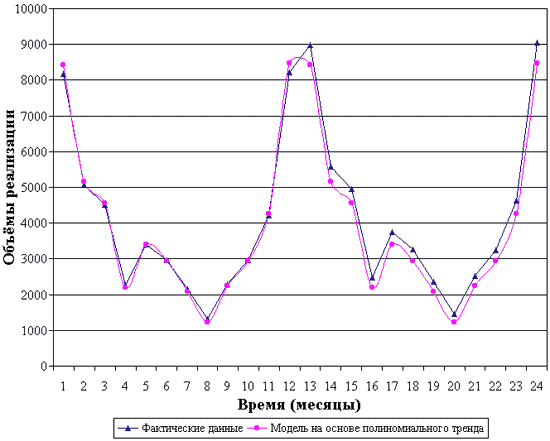
Рис. 5. Модель прогноза объёма продаж
Таким образом, прогноз на январь третьего сезона определяется следующим образом.
Определяем прогнозное значение модели:
F м t = 1 924,92 + 162,44 =2087 ± 7,8 (руб.)
Фактическое значение объёма продаж в предыдущем году (F ф t-1) составило 2 361руб. Принимаем коэффициент сглаживания 0.8. Получим прогнозное значение объёма продаж:
F пр t = 0,8*2 361 + (1-0.8) *2087 = 2306,2 (руб.)
Кроме того, для повышения надёжности прогноза рекомендуется строить все возможные сценарии прогноза и рассчитывать доверительный интервал прогноза.
Дмитриев Михаил Николаевич, заведующий кафедрой экономики и предпринимательства Нижегородского архитектурно-строительного университета (ННГАСУ), доктор экономических наук, профессор.
Адрес: 603000, Н. Новгород, ул. Горького, д. 142а, кв. 25.
Тел. 37-92-19 (дом) 30-54-37 (раб.)
Кошечкин Сергей Александрович, кандидат экономических наук, ст. преподаватель кафедры экономики и предпринимательства Нижегородского архитектурно-строительного университета (ННГАСУ).
Адрес: 603148, Н. Новгород, ул. Чаадаева, д. 48, кв. 39.
Тел. 46-79-20 (дом) 30-53-49 (раб.)
Отметим, что здесь рассматривалась сезонная компонента с длиной сезонности, равной 4 (4 квартала). Если исходные данные представлены помесячной динамикой (12 месяцев), то и сезонная компонента будет содержать 12 индексов сезонности вместо четырех. Процедура их вычисления при этом остается аналогичной.
Пример. Подбор наилучшей модели прогноза (модель Винтера)
Приведем пример выбора метода прогнозирования с использованием ранее рассмотренной информации на основе процедуры ППП Statgraphics «Forecasting– прогнозирование», как это указано на рис. 58.
Рис. 58. Выбор процедуры «прогнозирование» в ППП Statgraphics
Процедура «Forecasting» предусматривает возможность выбирать среди нескольких моделей прогноза (в том числе и модель Винтера) наилучшую модель, ориентируясь на ошибки прогноза.
Для того чтобы можно было использовать модель Винтера, необходимо в установках процедуры прогнозирования указать длину сезонности, а это автоматически включает процедуру учета сезонности при любой выбранной модели, что и отражено в отчете (рис. 59). Данная процедура позволяет выбирать одновременно 5 типов моделей, которые можно сравнивать по точности на основе ранее рассмотренных показателей точности прогноза.
В нашем случае наиболее точной оказалась модель (В) – линейный тренд (с учетом сезонной компоненты). Точность моделей можно сравнивать по различным показателям, например, по столбцу RMSE– стандартной ошибке прогноза (рис. 59).

Рис. 59. Отчет о выборе модели прогнозирования в ППП Statgraphicsс указанием длины сезонности
Перечислим модели, отраженные в отчете на рис. 59. В позиции (А) была назначена модель линейного экспоненциального сглаживания Холта. Как и отмечалось, для этой модели необходимы два параметра сглаживания: и. В позиции (В) была назначена модель линейного тренда. В позиции (С) – модель простого экспоненциального сглаживания. В позиции (D) – модель Брауна линейного экспоненциального сглаживания. В позиции (Е) – модель Винтера. Как видим, в последнем случае понадобилось три параметра сглаживания:,и.
Тот факт, что модель Винтера оказалась наименее точной, не означает, что она не пригодна для прогнозирования с учетом сезонной компоненты. Если убрать из установок процедуры прогнозирования указание на присутствие сезонности (не указывать длину сезонности), то среди всех выбранных модель Винтера будет наиболее точной, как это видно из отчета на рис. 60, в котором перечислен тот же набор моделей без указания на сезонность (модель Винтера здесь заменена квадратичной моделью Брауна).
Как видим, все приведенные модели имеют ошибку прогноза существенно бо льшую, чем модель Винтера на рис. 59.

Рис. 60. Отчет о выборе модели прогнозирования в ППП Statgraphicsс без указания длины сезонности
Отметим, что результаты прогнозирования по методу сезонной декомпозиции с линейным трендом, полученные ранее, оказались те же самые, что и при прогнозировании по линейному тренду на рис. 59 (сравните уравнение тренда на рис. 60 в позиции (В) и полученное в примере на основе табл. 3.1). Однако в последнем случае при проведении прогноза нет информации о составляющих элементов временного ряда (трендовой и сезонной), как это было получено ранее, но зато здесь прогноз может быть рассчитан в автоматическом режиме с указанием интервальных оценок.
Приведем прогноз по модели Винтера (рис. 61).

Рис. 61. Отчет о прогнозе по модели Винтера
На рис. 62 приведен график прогноза, иллюстрирующий результаты расчетов, приведенных на рис. 61.

Рис.62. График прогноза по модели Винтера
Пример. Моделирование сезонной компоненты на основе фиктивных переменных
Как отмечалось выше (п. 2.3.4), сезонную компоненту можно моделировать и на основе фиктивных переменных. Выберем в качестве примера аддитивную модель сезонной декомпозиции и проиллюстрируем ее сходство с моделью с фиктивными переменными.
Пусть имеются данные о продажах продукции фирмы (см. информацию в столбце Dataна рис. 63). Анализ горизонтального графика ряда (рис. 64) показал наличие тренда с сезонной компонентой. Применим метод сезонной декомпозиции (аддитивную модель), результаты которого показаны на рис. 63.

Рис. 63. Отчет о расчетах по методу сезонной декомпозиции по аддитивной модели

Рис. 64. Горизонтальный график ряда
Ниже приведены результаты усреднения сезонно-случайной компоненты в виде показателей, указывающих, на сколько усл. ден. единиц продажи выше или ниже средних по тренду.

Далее приведен график этих показателей (рис. 66). Слово «индекс» взят в кавычки потому, что здесь этот показатель выражен в абсолютных единицах изучаемого процесса (усл. ден. ед.), а не в долях или процентах, как это обычно присуще индексам в статистике.

Рис. 66. График «индекса» сезонности
По приведенным расчетным показателям заключаем, что продажи в первом квартале в среднем на 67,3 усл. ден. ед. меньше, чем по тренду, а в остальных кварталах – выше на соответствующую величину.
Приведенный ниже (рис. 67) график данных, исправленных на сезонность показывает наличие тренда, который можно принять за линейный. Рассчитаем по этим данным линейный тренд.

Рис. 67. График данных, исправленных на сезонность
Результаты расчета линейного тренда приведены ниже (рис. 68).

Рис. 68. Уравнение линейного тренда (R 2 = 87,5%,d= 1,82)
Итак, уравнение тренда имеет вид
 = 223.16 + 4.85t.
= 223.16 + 4.85t.
Проведем теперь моделирование сезонной компоненты с помощью фиктивных переменных. Как уже отмечалось, число таких переменных должно быть на единицу меньше, чем число уровней моделируемого явления. Т. к. у нас квартальные данные, то таких переменных будет три: х 1 , х 2 и х 3 . Каждая из них равна единице для соответствующего квартала и равна нулю – для остальных, как это отражено на рис. 69.

Рис. 69. Исходные данные для модели с фиктивными переменными
Результаты множественной регрессии с фиктивными переменными приведены на рис. 70.

Рис. 70. Отчет о множественной регрессии при моделировании сезонной компоненты с помощью фиктивных переменных
Итак, уравнение регрессии имеет вид (с округлением)
 = 240.9 + 4,94t– 82,71x 1 – 5,27x 2 + 14,04x 3 .
= 240.9 + 4,94t– 82,71x 1 – 5,27x 2 + 14,04x 3 .
Таким образом, по сравнению с четвертым кварталом продажи в первом квартале ниже на 82,7 1 ед., во втором – ниже на 5,27 ед., а в третьем – выше на 14,04 ед. Средний постоянный уровень продаж равен 240.9 ед., а среднее ежеквартальное увеличение продаж равно 4,94 ед. (коэффициент при t).
Аналогичные результаты можно получить, сравнивая сезонные «индексы» для аддитивной модели. Так, разница между такими индексами для соответствующих кварталов следующая: S 4 –S 1 = 20,26 – (–67,32) = 87,58;S 4 –S 2 = 20,26 – 13,56 = 6,7;
S 4 –S 3 = 20,26 – 33,49 = –13,23.
Задания для самостоятельной работы
Задание 1
К следующим временным рядам подобрать лучшую линию тренда в виде аналитической кривой:
а) 21,6 22,9 25,5 21,9 23,9 27,5 31,5 29,7 28,6 31,4 32,1 31,2;
б) 146 106 123 89 97 74 80 53 56 35.
Изобразить в системе координат исходные данные и выбранную линию тренда.
Ниже (рис. 71 и рис. 72) приведены отчеты о решении задач с помощью статистического ППП. Вам необходимо его проанализировать и сделать соответствующие выводы по аналогии с тренировочным примером.

Рис. 71. Информация для решения задачи а)

Рис. 72. Информация для решения задачи б)
Прогноз сделать по линейному и квадратичному тренду.
Задание 2
Имеется следующая информация о потреблении электроэнергии жителями города за 4 года по кварталам (рис.73 в столбце Data ).
Используя результаты расчетов (рис. 73), построить график исходных данных и линию тренда по центрированным скользящим средним (столбец Trend - Cycle рис.73). Вычислить индексы сезонности, усреднив показатели сезонности (столбецSeasonality ) по соответствующим кварталам (например, для 3-го квартала необходимо сосчитать среднюю арифметическую из чисел с номерами 3, 7, и 11 в столбцеSeasonality и т. д.).

Рис. 73. Информация для анализа задачи из задания 2
Построить график индексов сезонности.
Спрогнозировать потребление электроэнергии по линии тренда (выбрать лучшую линию тренда по данным на рис. 58)

Рис. 74. Окно отчета о подборе линии тренда
Скорректировать прогноз по тренду с помощью индексов сезонности.
Задание 3
Для следующего ряда данных об объемах продаж некоторой фирмы по кварталам спрогнозировать объемы продаж на очередной 6-й год, выбрав наилучший тип модели:
350, 200, 150, 400, 550, 350, 250, 550, 550, 400, 350, 600, 750, 500, 400, 650, 850, 600, 450, 700.
Задание 4
Спрогнозировать на очередные 5 периодов процесс, характеризующийся следующими данными за 40 прошедших периодов, подобрав наилучший вид модели:
10,4 10,34 10,55 10,46 10,82 10,91 10,87 10,67 11,11 10,00 11,20 11,27 11,44 11,52 12,10 11,83 12,62 12,41 12,43 12,73 13,01 12,74 12,73 12,76 12,92 12,64 12,79 13,06 12,69 13,01 12,90 13,12 12,47 12,94 13,1 12,91 13,39 13,13 13,34 13,14.
В этой статье мы на примере рассмотрим один из статистических методов прогнозирования продаж. Мы будем прогнозировать прибыль, а точнее размер месячной прибыли. Совершенно аналогично можно делать прогнозы и других показателей продаж: выручка, объем продаж в натуральных единицах, количество сделок, количество новых клиентов и т.д.
Описанный в статье метод прост (относительно, конечно) и не привязан к специализированным программам. В принципе, для составления прогноза достаточно было бы бумаги, карандаша, калькулятора и линейки. Однако, это очень трудоемкий способ, поскольку в процессе возникает много рутинных вычислений. Поэтому мы будем использовать Microsoft Excel (версии 2000).
Помимо простоты у метода есть еще один важный плюс: для прогноза требуется небольшая статистика. Сделать прогноз на 2-3 месяца вперед можно, если есть статистика хотя бы за 13-14 месяцев. Ну а большая статистика дает возможность и прогноз делать на больший период.
Сбор и подготовка статистики продаж
Прогнозирование начинается, конечно, со сбора статистики продаж. Здесь нужно обращать внимание на то, чтобы все сделки были более-менее одного «масштаба», и чтобы количество сделок в месяц было достаточно большое.
Например, розничный магазин. Даже в небольшом магазине в месяц могут делаться тысячи и даже десятки тысяч покупок. Сумма каждой покупки, по сравнению с месячной выручкой, весьма мала — 0,0..01% от выручки. Это хорошая ситуация для прогнозирования.
Если прогноз делается для компании, работающей на корпоративном рынке, то нужно следить, чтобы количество сделок в месяц было хотя бы не менее 100, иначе для прогнозирования нужно применять другие методы. Также, если в статистике продаж встречаются крупные сделки, с суммой, например, около 10% от месячной выручки, то такие сделки надо исключать из статистики и рассматривать отдельно (опять же другими методами). Если крупные сделки не исключить, то они создадут в динамике «выбросы», которые могут сильно ухудшить точность прогноза.
По этим данным мы будем составлять прогноз на 12 месяцев вперед.
| Период | № Периода | Прибыль | Период | № Периода | Прибыль |
| 2004-7 | 1 | 839 | 2005-5 | 11 | 3069 |
| 2004-8 | 2 | 1714 | 2005-6 | 12 | 2220 |
| 2004-9 | 3 | 2318 | 2005-7 | 13 | 1653 |
| 2004-10 | 4 | 2629 | 2005-8 | 14 | 3115 |
| 2004-11 | 5 | 2823 | 2005-9 | 15 | 3961 |
| 2004-12 | 6 | 3320 | 2005-10 | 16 | 4514 |
| 2005-1 | 7 | 3316 | 2005-11 | 17 | 4644 |
| 2005-2 | 8 | 3479 | 2005-12 | 18 | 5066 |
| 2005-3 | 9 | 3388 | 2006-1 | 19 | 4934 |
| 2005-4 | 10 | 3263 | - | - | - |
Рис. 1. График помесячной прибыли, данные из таблицы .
Существуют две основные модели временного ряда: аддитивная и мультипликативная. Формула аддитивной модели: Y t = T t + S t + e t Формула мультипликативной модели: Y t = T t x St + e t Обозначения: t - время (месяц или другой период детализации); Y - значение величины; Т — тренд; S — сезонные изменения; е - шум. Разница между моделями хорошо видна на рисунке , где приведены два ряда, с одинаковыми трендами, один ряд — по мультипликативной модели, другой — по аддитивной.
-
Примечание. Могут встречаться такие показатели продаж, у которых сезонные колебания практически отсутствуют.

Рис. 2. Примеры рядов: слева — по аддитивной модели; справа — по мультипликативной.
В нашем примере мы будем использовать мультипликативную модель.
Для каких-либо других данных, возможно лучше подошла бы аддитивная модель. Узнать на практике, какая модель подходит лучше, можно либо интуитивно, либо методом проб и ошибок.
Выделение тренда
В формулах моделей рядов динамики (Y t = T t + S t + e t и Y t = T t S t + e t ) фигурирует тренд T t , такой тренд мы будем называть «точным».
В практических задачах выделить точный (вернее, «почти точный») тренд T t может оказаться технически очень сложно (см. например, пункт в списке литературы).
Поэтому мы будем рассматривать приближенные тренды. Самый простой способ получения приближенного тренда — сглаживание ряда методом скользящего среднего с периодом сглаживания равным максимальному периоду сезонных колебаний. Сглаживание почти полностью устранит сезонные колебания и шум.
В рядах с детализацией по месяцам сглаживание нужно делать по 12-ти точкам (то есть по 12-ти месяцам). Формула скользящего среднего с периодом сглаживания 12 месяцев:
![]()
Где M t — значение скользящего среднего в точке t ; Y t — значение величины временного ряда в точке t .
-
Примечание. Очень редко, но все-же бывают динамики продаж, где длина полного период не только не равна году, но и «плавает». В таких случаях колебания, видимо, вызваны не сезонными изменениями, а какими-то другими, более мощными факторами.
Обратите внимание: поскольку мы вычисляем некоторый средний тренд за последние 12 месяцев, то в поведении приближенного тренда по сравнению с точным, происходит как бы запаздывание на 6 месяцев. Не смотря на то, что тренд, полученный методом скользящего среднего — это не точный, а приближенный (да еще и с запаздыванием), он вполне подходит для нашей задачи.
Прологарифмируем уравнение мультипликативной модели, и если шум e t не очень большой, то получим аддитивную модель.
Здесь ε 1;t также обозначает шум. Тренд мы выделим (скользящим средним за 12 месяцев) именно для такой преобразованной модели. На рисунке 3 — графики и показателя и тренда M t .

Рис. 3. График прологарифмированной величины показателя и тренда М и
скользящего среднего по 12-ти месяцам. Слева на одном графике и величина и тренд. Справа — тренд в увеличенном масштабе. По оси X — номера периодов.
-
Примечание. Если темпы динамики небольшие, скажем, 10-15% в год, то и с мультипликативной моделью можно работать как с аддитивной (не логарифмирую).
Прогноз тренда
Тренд мы получили, теперь нужно его спрогнозировать. Прогноз можно бы было получить, например, методом экспоненциального сглаживания (см. ), но поскольку мы хотим прогнозировать максимально простым методом, то остановимся на обычной параметрической аппроксимации. В качестве функций приближения используем следующий набор:
Линейная функция: y = a + b × t.
Логарифмическая функция: y = a + b × ln(t)
Полином второй степени: y = a + b × t + c × t 2
Степенная функция: y = a × t b
Экспоненциальная функция: y = a × e b × t
Хорошо бы было дополнить набор и другими функциями, но для этого возможностей Excel недостаточно, нужно использовать специализированные программы: Maple, Matlab, MathCad и т.д.
Качество приближения мы будем оценивать по величине достоверности аппроксимации R 2 . Чем ближе эта величина к 1 — тем лучше функция приближает тренд. Это верно не всегда, но в Excel нет других критериев оценки качества аппроксимации. Впрочем, критерия R 2 нам будет достаточно.
На рисунках 4, 5, 6, 7 и 8и мы сделали аппроксимацию нашего тренда различными функциями и каждая функция аппроксимации продолжена на 12 точек вперед. И еще одна аппроксимация — на рисунке 9, полиномом 5-той степени.

Обратите внимание: если некоторая функция хорошо приближает тренд, то это не всегда означает, что данная функция хорошо тренд прогнозирует. В нашем примере полином 5-той степени делает самое лучшее приближение по сравнению с другими функциями (R 2 = 1) и, одновременно, дает самый нереальный прогноз.

По рисункам мы видим, что значение R 2 ближе всего к единице у параболы (полином 5-той степени уже не рассматриваем). Следующая по качеству аппроксимация — прямая линия. Хотя формально парабола аппроксимирует лучше всех, но ее поведение, особенно перевал в отдаленных точках, представляется не очень правдоподобным. Тогда можно взять аппроксимацию прямой, но мы найдем компромисс: среднее арифметическое между параболой и прямой.

Рис. 10. Тренд M t и его прогноз. По оси X — номер периода.
Результат прогноза тренда M t — на рисунке 10. Итак, мы получили прогноз тренда.
Прогноз показателя
Прогноз тренда у нас есть. Теперь можно сделать прогноз самого показателя. Формула очевидна:
Ln(Y t+1) = 12 × M t+1 - Ln(Y t) - Ln(Y t-1) - ... - Ln(Y t-10)
Y t+1 = exp(Ln(Y t+1))
До периода t = 19 у нас есть фактические данные. Для t = 20..31 у нас есть спрогнозированный тренд M t , а значения показателя мы будем считать последовательно, сначала для t = 20, потом для t = 21 и т.д.
Результаты прогноза — на рисунке 11 и в таблице 2.

Рис. 11. Прогноз показателя. По оси X — номер периода.
Сравнение прогноза и реальных данных
На рисунке 12 — графики прогноза и фактических данных.
В таблице 3 приведено сравнение реальных данных и спрогнозированных. Посчитаны ошибки прогноза, абсолютные: Прогноз-Факт; и относительные: 100%*(Прогноз-Факт)/Факт.
Обратите внимание, что ошибки прогноза смещены в положительную сторону. Причина этого может быть как в несовершенстве метода, так и в каких-то объективных обстоятельствах, например, в изменении ситуации на рынке в прогнозируемом периоде.
Точность прогноза
| Период | № Периода | М | Ln(Y) | Y |
| 2006-2 | 20 | 8,1861 | 8,6494 | 5707 |
| 2006-3 | 21 | 8,2205 | 8,5408 | 5119 |
| 2006-4 | 22 | 8,2531 | 8,4816 | 4825 |
| 2006-5 | 23 | 8,2839 | 8,3987 | 4441 |
| 2006-6 | 24 | 8,3129 | 8,0533 | 3144 |
| 2006-7 | 25 | 8,3401 | 7,7367 | 2291 |
| 2006-8 | 26 | 8,3655 | 8,3488 | 4225 |
| 2006-9 | 27 | 8,3891 | 8,5675 | 5258 |
| 2006-10 | 28 | 8,4109 | 8,6765 | 5864 |
| 2006-11 | 29 | 8,4309 | 8,6833 | 5904 |
| 2006-12 | 30 | 8,4491 | 8,7487 | 6303 |
| 2007-1 | 31 | 8,4655 | 8,7007 | 6007 |

Рис. 12. Фактические данные и спрогнозированные. По оси X — номер периода.
Даже если модель очень хорошо описывает динамику реальных данных, что в общем-то большая редкость, то остаются еще шумы, которые вносят свою ошибку. Например, если уровень шума составляет 10% от значения показателя, то и ошибка прогноза будет не меньше 10%. Плюс, как минимум, еще несколько процентов ошибки добавятся из-за несоответствия модели и динамики реальных данных.
А вообще, лучший способ определить точность — это многократно делать прогнозы для одного и того же процесса и на основании такого опыта определять точность эмпирически.
| Период | № Периода | Факт | Прогноз | Ошибка, абс. | Ошибка, % |
| 2006-2 | 20 | 5233 | 5707 | 474 | 9 |
| 2006-3 | 21 | 4625 | 5119 | 494 | 11 |
| 2006-4 | 22 | 4776 | 4825 | 49 | 1 |
| 2006-5 | 23 | 4457 | 4441 | -16 | 0 |
| 2006-6 | 24 | 3169 | 3144 | -25 | -1 |
| 2006-7 | 25 | 2054 | 2291 | 237 | 12 |
| 2006-8 | 26 | 3549 | 4225 | 676 | 19 |
| 2006-9 | 27 | 5087 | 5258 | 171 | 3 |
| 2006-10 | 28 | 5187 | 5864 | 677 | 13 |
| 2006-11 | 29 | 5287 | 5904 | 617 | 12 |
| 2006-12 | 30 | 5700 | 6303 | 603 | 11 |
| 2007-1 | 31 | 4689 | 6007 | 1318 | 28 |
Заключение и список литературы
В этой статье мы рассмотрели сильно упрощенный метод прогнозирования. Тем не менее, при отсутствии резких изменений на рынке и внутри компании, даже такой простой метод дает удовлетворительную точность прогноза месяцев на 10 вперед.
Литература
1. Крамер Г. «Математические методы статистики».— М.: «Мир», 1975.
2. Кендэл М. «Временные ряды».— М.: «Финансы и статистика», 1981.
3. Андерсон Т. «Статистический анализ временных рядов».— М.: «Мир», 1976.
4. Бокс Дж., Дженкис Г. «Анализ временных рядов. Прогноз и управление».— М.: «Мир», 1976
5. Губанов В.А., Ковальджи А.К. «Выделение сезонных колебаний на основе вариационных принципов. Экономика и математические методы». 2001. т. 37. № 1. С. 91-102.
В данной статье рассмотрен один из основных методов прогнозирования - анализ временных рядов. На примере розничного магазина с помощью данного метода определены объемы продаж на прогнозный период.
Одна из главных обязанностей любого руководителя - грамотно планировать работу своей компании. Мир и бизнес сейчас меняются очень стремительно, и успеть за всеми изменениями непросто. Многие события, которые невозможно предусмотреть заранее, меняют планы фирмы (например, выпуск нового продукта или группы товаров, появление на рынке сильной компании, объединение конкурентов). Но надо понимать, что зачастую планы нужны лишь для того, чтобы вносить в них коррективы, и в этом нет ничего страшного.
Любой процесс прогнозирования, как правило, строится в следующей последовательности:
1. Формулировка проблемы.
2. Сбор информации и выбор метода прогнозирования.
3. Применение метода и оценка полученного прогноза.
4. Использование прогноза для принятия решения.
5. Анализ «прогноз-факт».
Все начинается с корректной формулировки проблемы. В зависимости от нее задача прогнозирования может быть сведена, например, к задаче оптимизации. Для краткосрочного планирования производства не так важно, каким будет объем продаж в ближайшие дни. Важнее максимально эффективно распределить объемы производства продукции по имеющимся мощностям.
Краеугольным ограничением при выборе метода прогнозирования будет исходная информация: ее тип, доступность, возможность обработки, однородность, объем.
Выбор конкретного метода прогнозирования зависит от многих моментов. Достаточно ли объективной информации о прогнозируемом явлении (существует ли данный товар или аналоги достаточно долго)? Ожидаются ли качественные изменения изучаемого явления? Имеются ли зависимости между изучаемыми явлениями и/или внутри массивов данных (объемы продаж, как правило, зависят от объемов вложений в рекламу)? Являются ли данные временным рядом (информация о наличии собственности у заемщиков не является временным рядом)? Имеются ли повторяющиеся события (сезонные колебания)?
Независимо от того, в какой отрасли и сфере хозяйственной деятельности работает фирма, ее руководству постоянно приходится принимать решения, последствия которых проявятся в будущем. Любое решение основывается на том или ином способе проведения. Одним из таких способов является прогнозирование.
Прогнозирование - это научное определение вероятных путей и результатов предстоящего развития экономической системы и оценка показателей, характеризующих это развитие в более или менее отдаленном будущем.
Рассмотрим прогнозирование объема продаж, используя метод анализа временных рядов.
Прогнозирование на основе анализа временных рядов предполагает, что происходившие изменения в объемах продаж могут быть использованы для определения этого показателя в последующие периоды времени.
Временной ряд - это ряд наблюдений, проводящихся регулярно через равные промежутки времени: год, неделю, сутки или даже минуты, в зависимости от характера рассматриваемой переменной.
Обычно временной ряд состоит из нескольких компонентов:
1) тренда - общей долгосрочной тенденции изменения временного ряда, лежащей в основе его динамики;
2) сезонной вариации - краткосрочного регулярно повторяющегося колебания значений временного ряда вокруг тренда;
3) циклических колебаний, характеризующих так называемый цикл деловой активности, или экономический цикл, состоящий из экономического подъема, спада, депрессии и оживления. Этот цикл повторяется регулярно.
Для объединения отдельных элементов временного ряда можно воспользоваться мультипликативной моделью:
Объем продаж = Тренд × Сезонная вариация × Остаточная вариация. (1)
В ходе составления прогноза продаж учитывают показатели компании за последние несколько лет, прогноз роста рынка, динамику развития конкурентов. Оптимальное прогнозирование продаж и корректировку прогноза обеспечивает полный отчет о продажах компании.
Применим данный метод для определения объема продаж салона «Часы» на 2009 г. В табл. 1 представлены объемы продаж салона «Часы», специализирующегося на розничной продаже часов.
Таблица 1. Динамика объема продаж салона «Часы», тыс. руб.
Для данных, приведенных в табл. 1, отметим два основных момента:
существующий тренд : объем продаж в соответствующих кварталах каждого года стабильно растет год от года;
- сезонная вариация: в первые три квартала каждого года продажи медленно растут, но остаются на относительно низком уровне; максимальные за год значения объема продаж всегда приходятся на четвертый квартал. Такая динамика повторяется из года в год. Данный тип отклонений всегда носит название сезонных, даже если речь идет, например, о временном ряде еженедельных объемов продаж. Этот термин просто отражает регулярность и краткосрочность отклонений от тренда по сравнению с продолжительностью временного ряда.
Первый этап анализа временных рядов - построение графика данных.
Для того чтобы составить прогноз, необходимо сначала рассчитать тренд, а затем - сезонные компоненты.
Расчет тренда
Тренд - это общая долгосрочная тенденция изменения временного ряда, лежащего в основе его динамики.
Если посмотреть на рис. 2, то через точки гистограммы можно от руки начертить линию повышательного тренда. Однако для этого есть математические методы, позволяющие оценить тренд более объективно и точно.
Если у временного ряда есть сезонная вариация, обычно применяют метод скользящей средней.Традиционным методом прогнозирования будущего значения показателя является усреднение n его прошлых значений.
Математически скользящие средние (служащие оценкой будущего значения спроса) выражаются так:
Скользящая средняя = Сумма спроса за предыдущие n-периоды / n. (2)
Средний объем продаж за первые четыре квартала = (937,6 + 657,6 + 1001,8 + 1239,2) / 4 = 959,075 тыс. руб.
Когда квартал заканчивается, данные об объеме продаж в течение последнего квартала прибавляются к сумме данных за предыдущие три квартала, а данные за ранний квартал отбрасываются. Это приводит к сглаживанию краткосрочных нарушений в ряде данных.
Средний объем продаж за следующие четыре квартала = (657,6 + 1001,8 + 1239,2 + 1112,5) / 4 = 1002,775 тыс. руб.
Первая рассчитанная средняя показывает средний объем продаж за первый год и находится посередине между данными о продажах за II и III кварталы 2007 г. Средняя за следующие четыре квартала разместится между объемом продаж за III и IV кварталы. Таким образом, данные столбца 3 - это тренд скользящих средних.
Но для продолжения анализа временного ряда и расчета сезонной вариации необходимо знать значение тренда точно на то же время, что и исходные данные, поэтому необходимо центрировать полученные скользящие средние, сложив соседние значения и разделив их пополам. Центрированная средняя и есть значение рассчитанного тренда (расчеты представлены в столбцах 4 и 5 табл. 2).
Таблица 2. Анализ временного ряда
|
Объем продаж, тыс. руб. |
Четырехквартальная скользящая средняя |
Сумма двух соседних значений |
Тренд, тыс. руб. |
Объем продаж / тренд × 100 |
|
|
I кв. 2007 г. | |||||
|
II кв. 2007 г. | |||||
|
III кв. 2007 г. | |||||
|
IV кв. 2007 г. | |||||
|
I кв. 2008 г. | |||||
|
II кв. 2008 г. | |||||
|
III кв. 2008 г. | |||||
|
IV кв. 2008 г. |
Для составления прогноза продаж на каждый квартал 2009 г. надо продолжить на графике тренд скользящих средних. Так как процесс сглаживания устранил все колебания вокруг тренда, то сделать это будет несложно. Распространение тренда показано линией на рис. 4. По графику можно определить прогноз для каждого квартала (табл. 3).
Таблица 3. Прогноз тренда на 2009 г.
|
2009 г. |
Объем продаж, тыс. руб. |
Расчет сезонной вариации
Для того чтобы составить реалистичный прогноз продаж на каждый квартал 2009 г., необходимо рассмотреть поквартальную динамику объема продаж и рассчитать сезонную вариацию. Если обратиться к данным о продажах за предыдущий период и пренебречь трендом, можно рассмотреть сезонную вариацию более четко. Так как для анализа временного ряда будет использована мультипликативная модель , необходимо разделить каждый показатель объема продаж на величину тренда, как показано в следующей формуле:
Мультипликативная модель = Тренд × Сезонная вариация × Остаточная вариация × Объем продаж / Тренд = Сезонная вариация × Остаточная вариация. (3)
Результаты расчетов представлены в столбце 6 табл. 2. Для того чтобы выразить значения показателей в процентах и округлить их до первого десятичного знака, умножаем их на 100.
Теперь будем по очереди брать данные за каждый квартал и устанавливать, на сколько в среднем они больше или меньше значений тренда. Расчеты приведены в табл. 4.
Таблица 4. Расчет средней квартальной вариации, тыс. руб.
|
I квартал |
II квартал |
III квартал |
IV квартал |
|
|
Нескорректированная средняя | ||||
Нескорректированные данные в табл. 4 содержат как сезонную, так и остаточную вариацию. Для удаления элемента остаточной вариации необходимо скорректировать средние. В долгосрочном плане величина превышения объема продаж над трендом в удачные кварталы должна уравниваться с величиной, на которую объем продаж ниже тренда в неудачные кварталы, чтобы сезонные компоненты в сумме составляли примерно 400 %. В данном случае сумма нескорректированных средних равна 398,6. Таким образом, необходимо умножить каждое среднее значение на корректирующий коэффициент, чтобы сумма средних составила 400.
Корректирующий коэффициент рассчитывается следующим образом: Корректирующий коэффициент = 400 / 398,6 = 1,0036.
Расчет сезонной вариации представлен в табл. 5.
Таблица 5. Расчет сезонной вариации
На основании данных табл. 5 можно спрогнозировать, например, что в I квартале объем продаж в среднем будет составлять 96,3 % значения тренда, в IV - 118,1 % значения тренда.
Прогноз продаж
При составлении прогноза продаж исходим из следующих предположений:
динамика тренда останется неизменной по сравнению с прошлыми периодами;
сезонная вариация сохранит свое поведение.
Естественно, это предположение может оказаться неверным, придется вносить коррективы, учитывая экспертное ожидаемое изменение ситуации. Например, на рынок может выйти другой крупный торговец часами и сбить цены салона «Часы», может измениться экономическая ситуация в стране и т. д.
Тем не менее, основываясь на вышеперечисленных предположениях, можно составить прогноз продаж по кварталам на 2009 г. Для этого полученные значения квартального тренда надо умножить на значение соответствующей сезонной вариации за каждый квартал. Расчет данных приведен в табл. 6.
Таблица 6. Составление прогноза продаж по кварталам салона «Часы» на 2009 г.
Из полученного прогноза видно, что товарооборот салона «Часы» в 2009 г. может составить 5814 тыс. руб., но для этого предприятию необходимо проводить различные мероприятия.
Полный текст статьи читайте в журнале "Справочник экономиста" №11 (2009 г.).
После моего прихода в компанию «Избёнка», осуществляющую розничную торговлю натуральной молочной продукцией, я думал, что помесячное прогнозирование остались для меня – в прошлом. Ведь из-за того, что стратегическим принципом компании является торговля только натуральной молочной продукцией, потребность в прогнозировании больше недели – отпадает. Всё дело в коротких сроках годности такой продукции – обычно это 3-5 дней. Однако мне пришлось вспоминать прошлые навыки, когда я столкнулся с необходимостью делать заказ на сыр. Дело в том, что он вызревает как раз около месяца. А чтобы через месяц получить у поставщика нужный объём, мне нужно уже сейчас сказать ему, сколько мне понадобится, чтобы он запустил в производственный процесс необходимое для этого количество сырья. А в случае поставок с большим сроком реагирования – будь то: из-за длинного транспортного плеча или трудоёмкого процесса производства возникает необходимость прогнозировать спрос на длительные сроки. Срок реагирования – это время от момента, когда приняли решение о необходимости закупки позиции, и до момента, когда её можно использовать на производстве или отпускать клиенту. При этом в компаниях обычно осуществляется помесячное планирование, поэтому и прогноз желательно иметь в разбивке по месяцам. Выполнение этого же условия требуется при револьверных поставках – то есть таких поставках, когда период между ними меньше срока реагирования:
|
январь |
февраль |
март |
апрель |
май |
июнь |
|
|
поставка №1 |
отгрузка |
доставка |
приёмка |
|||
|
поставка №2 |
отгрузка |
доставка |
приёмка |
|||
|
поставка №3 |
отгрузка |
доставка |
приёмка |
|||
|
поставка №4 |
отгрузка |
доставка |
приёмка |
В данном примере, срок реагирования составляет три месяца, а период между двумя соседними поставками – месяц. Таким образом, в каждый момент времени у нас всегда в пути находятся три поставки на разных этапах, а на остатках лежит не больше месячной потребности. Но, чтобы эта система работала корректно, нам опять же нужен помесячный прогноз.
При этом обычно необходимо прогнозировать спрос большого количества позиций, а во время прогнозирования мы должны учесть общую динамику спроса по каждой позиции и характерную ей сезонность продаж. Объём таких расчётов оказывается слишком большим для ручного прогнозирования, поэтому нашей задачей становится создание автоматического алгоритма прогнозирования для обработки имеющейся статистики прошлого спроса по всем позициям. Ниже в статье мы будем обсуждать обработку одного ряда спроса по одной позиции. Но по аналогии надо анализировать последовательно данные по всем имеющимся в компании позициям.
Упрощённый классический метод.
Первоначально необходимо определить общую динамику продаж: то есть для имеющегося ряда прошлого спроса S i надо построить линейный тренд – долговременную тенденцию изменения временного ряда, выражаемую прямой линией. В Microsoft Excel его уравнение можно получить, добавив на диаграмму временного ряда линейный тренд, а значение тренда для любого месяца Т i – используя функцию ТЕНДЕНЦИЯ. Именно благодаря этим значениям мы сможем рассчитать коэффициенты сезонности K i для каждого i -того месяца в прошлом. Для этого надо разделить значение фактического спроса за каждый месяц на значение линейного тренда за этот же месяц:
Тогда при наличии статистики хотя бы за два-три года появляется возможность рассчитать коэффициенты сезонности для каждого месяца года K m , где: К 1 – коэффициент сезонности января, К 2 – коэффициент сезонности февраля, К 3 – коэффициент сезонности марта, и так далее... Делается это за счёт усреднения всех полученных коэффициентов сезонности за все года для соответствующего месяца:
 ,
,
где L m – количество соответствующих месяцев в истории спроса.
Теперь, когда у нас есть эти коэффициенты, мы можем получить прогноз спроса P i на любой будущий i -тый месяц, умножив соответствующий этому месяцу коэффициент сезонности K m на значение тренда Т i для этого месяца: P i = K m · T i .
Данный метод отличается от классического только отсутствием скользящего годового усреднения. По классике коэффициенты сезонности надо получать делением не на линейный тренд, а на значения этого скользящего среднего, и линейный тренд строится по скользящему. Но из-за этого теряется год статистики спроса, включая полгода самых ценных – последних данных, а так как зачастую вся статистика продаж по позиции в компании составляет всего полтора-два года, то подобная роскошь оказывается слишком расточительной.
Индуктивный метод Разгуляева.
Данный метод был разработан мной для вычисления прогноза спроса в случаях, когда расчёт по классическому методу занимает слишком много времени из-за большого объёма информации или, вообще, невозможен из-за того, что тренд уходит в минус. Впоследствии он был реализован в нескольких автоматизированных системах, включая "Invertor" для "Эксель" и "Прогноз продаж" для "1С" (http://www.forecastsupply.ru/). Формула расчёта может показаться сначала сложной:

где X – это номер месяца, на который мы прогнозируем спрос, то есть количество месяцев, имеющихся в статистике прошлого спроса по позиции, плюс ещё один.
Но если мы обратим внимание на условие после каждой формулы в фигурной скобке, то увидим, что из всего этого каскада формул нам нужна только одна – та, которая подходит под наш объём имеющейся статистики прошлого спроса. Причём каждая формула состоит только из сложения, умножения и деления. Значок ∑ S i – просто означает, что нам надо просуммировать все значения прошлого спроса, начиная с месяца, номер которого указан снизу этого значка, и заканчивая месяцем, номер которого указан сверху этого значка. Таким образом, получается, что и для понимания, и для реализации в корпоративной информационной системе оказывается проще именно этот метод. И если численные методы нахождения тренда в корпоративной информационной системе компании могут реализовать только программисты со специальным математическим образованием, да и то – для них это будет задачка на неделю-две, то уж сложение, умножение и деление – вам внедрит в течение суток любой программист!.. Да и считаться данный алгоритм будет на порядок быстрее.
Кроме этого у данного метода есть ещё ряд существенных плюсов – он никогда не будет прогнозировать отрицательные значения спроса при положительной прошлой статистике в отличие от классического метода. А ещё он – гибче, то есть быстрее реагирует на проявления динамики спроса. При этом, как и классический метод, индуктивный метод Разгуляева учитывает: как общую динамику спроса, причём, не привязываясь к линейности тренда, так и повторяющиеся из года в год сезонные влияния. Единственный его «недостаток» заключается в том, что вы не можете посчитать прогноз спроса на любой месяц, не посчитав предварительно прогноз спроса на все предыдущие месяца. То есть, если сейчас закончился январь, и вы хотите спрогнозировать спрос в мае, то вам сначала надо будет по имеющейся статистике спрогнозировать спрос в феврале, затем внести это значение в статистику, и на её основании спрогнозировать спрос в марте. После этого по такой же схеме спрогнозировать спрос в апреле и только затем в мае. Однако на практике нам редко нужно прогнозировать спрос через полгода, но не прогнозировать спрос в следующем месяце, поэтому данный недостаток – не так критичен. Ещё одну проблему в применении данного метода – возможность равенства нулю одного из знаменателей в формуле, легко решает переход на формулу строчкой выше, где диапазон суммирования в знаменателе будет – значительно больше, и такой ситуации точно не возникнет. Ачтобы лучше разобраться с формулами, можно скачать Excel -файлы с примерами реализации обоих методов по ссылке:
Оценка точности прогноза.
Как только у нас появляются хотя бы два варианта прогнозирования – сразу же возникает вопрос: «А какой из них лучше?» – Однозначного ответа на него нет и быть не может, так как нет и никогда не будет самого лучшего метода прогнозирования – их надо проверять на ваших данных, чтобы оценить, какой из них лучше предсказывает ситуацию для ваших позиций в ваших каналах продаж. И здесь исследователей подстерегает одна ловушка в определении ошибки прогноза D . Самым распространённым вариантом расчёта такой ошибки является следующая формула:
где: P – это прогноз, а S – факт за тот же месяц.
Однако когда спрашиваешь пользователя этой формулы: «А чему равна ошибка, если факт равен нулю?» – то он попадает в понятное затруднение, ведь на ноль делить нельзя. Некоторые отвечают, что в таком случае D = 100% – мол, мы полностью ошиблись. Однако простой пример показывает, что такой ответ тоже – не верен:
|
вариант |
прогноз |
факт |
ошибка прогноза |
|
№1 |
100% |
||
|
№2 |
300% |
||
|
№3 |
Оказывается, что в варианте развития событий №2, когда мы лучше угадали спрос, чем в варианте №1, ошибка по данной формуле оказалась – больше. То есть ошиблась уже сама формула. Есть и другая проблема, если мы посмотрим на варианты №2 и №3, то увидим, что имеем дело с зеркальной ситуацией в прогнозе и факте, а ошибка при этом отличается – в разы!.. То есть при такой оценке ошибки прогноза нам лучше его заведомо делать менее точным, занижая показатель – тогда ошибка будет меньше!.. Хотя понятно, что чем точнее будет прогноз – тем лучше будет и закупка. Поэтому для расчёта ошибки советую использовать следующую формулу:
 .
.
№1
100%
№2
№3
Как мы видим в варианте №1 ошибка становится равной 100%, причём это уже – не наше предположение, а чистый расчёт, который можно доверить машине. Зеркальные же варианты №2 и №3 – имеют и одинаковую ошибку, причём эта ошибка меньше ошибки самого плохого варианта №1. Единственная ситуация, когда данная формула не сможет дать однозначный ответ – это равенство знаменателя нулю. Но максимум из прогноза и факта равен нулю, только когда они оба равны нулю. В таком случае получается, что мы спрогнозировали отсутствие спроса, и его, действительно, не было – то есть ошибка тоже равна нулю – мы сделали совершенно точное предсказание.
Получение истории спроса.
На протяжении всей предыдущей статьи мы работали с временны м рядом прошлого спроса, однако обычно его в явном виде изначально в компании – нет. Дело в том, что данные о прошлых продажах, далеко не всегда являются историей спроса. Получению этой истории из имеющихся в корпоративной информационной системе данных можно посвятить целую статью – здесь же ограничимся перечислением влияющих факторов с небольшим объяснением по каждому.
Дефицит. Если товара не было, и продажи из-за этого были равны нулю, то данную статистику ни в коем случае нельзя использовать в «чистом» виде – ведь в таком случае мы будем сами создавать ситуацию такого же дефицита и в будущем. Поэтому дефицит нужно оценивать и прибавлять к продажам, чтобы получить историю спроса с его учётом.
Нехарактерно большой спрос. Иногда к нам приходят клиенты, которые забирают весь запас, или даже мы делаем дополнительный заказ под них. Такие отгрузки крайне редки, и держать под них запас – не выгодно, так как мы больше потеряем на хранение таких объёмов и обслуживание замороженных в запасы денег, чем выиграем от такой продажи, которой может больше никогда и не случиться. Однако в историю продаж эти операции попадают, и значит, их надо исключать.
Проведение маркетинговых акций. В случае если наши продажи были завышенными из-за проведения маркетинговых акций, то такую статистику продаж тоже нужно корректировать. Самый опасный случай – когда мы устраиваем распродажу неликвидов,они начинают продаваться, и мы на основании этих данных решаем ещё их закупить.
Отсутствие товаров-аналогов. На завышенный спрос может повлиять и отсутствие товаров-аналогов, когда клиент, не найдя то, за чем пришёл, берёт хоть что-нибудь подходящее – например позицию, спрос на которую мы хотим предсказать. При этом если вы в будущем не собираетесь допускать таких ситуаций, то спрос на исследуемую позицию заведомо не будет таким высоким.
Товары, отсутствие которых запирает продажи других позиций. В случае, когда у нас какие-то две позиции продаются обычно вместе, но какой-то одной из них долго не было, возможно, что продажи другой – тоже были заниженными. Например, если в нашей торговой точке не было сметаны, то и творог будет продаваться хуже. А значит, данную зависимость тоже надо учитывать и корректировать соответствующим образом прогнозы.
Цены. Всем понятно, что цена оказывают значительное влияние на объём продаж, а значит, в прогнозировании нам надо будет учитывать и этот фактор, если мы хотим добиться необходимой точности наших расчётов.
Валерий Разгуляев
Перепечатка и перепостинг статьи вместе с этим текстом, указанием автора, и ссылки на перво